
Reliable AI Solution Engineering is the systematic process of designing, building, deploying, and maintaining artificial intelligence systems that are secure, scalable, predictable, and directly aligned with business objectives. Unlike traditional software engineering—which relies on hard-coded, deterministic rules—AI engineering manages probabilistic models that learn and adapt from data. Making these solutions “reliable” means moving beyond fragile, local proofs-of-concept to create production-grade enterprise applications equipped with strict data governance, continuous monitoring for performance degradation, robust security guardrails, and automated deployment pipelines (MLOps/LLMOps). Ultimately, it ensures that an AI system performs consistently, safely, and cost-effectively in the real world without hallucinating, leaking sensitive data, or collapsing under enterprise workloads.
While experimenting with Artificial Intelligence has become incredibly easy, scaling it into a dependable business solution is notoriously difficult. If you are an enterprise leader, an ambitious developer, or a technology strategist trying to understand how to bridge the gap between AI hype and actual value, this guide will walk you through the realities, frameworks, and statistics of reliable AI engineering today.
The Core Concept: Moving from Prototype to Production
In the current technological landscape, building a “cool demo” using an API from OpenAI, Anthropic, or Google is something a junior developer can achieve in an afternoon. However, taking that same generative AI feature and deploying it across a multinational corporation—where it must securely handle proprietary data, adhere to compliance laws, and operate with 99.9% uptime—requires rigorous AI Solution Engineering.
This gap between prototype and production is often referred to as Pilot Paralysis. Organizations frequently launch proofs-of-concept (PoCs) without clear production pathways, consuming vast resources without generating tangible value.
Recent data highlights how severe this bottleneck has become:
- A landmark report from MIT’s Project NANDA revealed a staggering 95% failure rate for custom enterprise generative AI pilots trying to reach production with measurable impact.
- Broader technology assessments put the general AI project failure rate at over 80%—roughly double the failure rate of non-AI technology projects.
- According to S&P Global’s recent enterprise survey, the average organization scrapped 46% of its AI proofs-of-concept before they ever reached end-users.
Reliable AI Solution Engineering is the discipline specifically created to solve this exact problem. It shifts the focus away from merely “tuning a model” toward architecting resilient, end-to-end systems that deliver measurable Return on Investment (ROI).
Why “Reliable” Matters Now More Than Ever
To understand the necessity of reliability, we must look at the financial and operational consequences of AI failures. We are no longer in the era of simple recommendation algorithms; we are entering the era of Agentic AI, where systems have the autonomy to execute tasks, modify infrastructure, and interact directly with customers.
1. The High Cost of Hallucinations and Errors
When an AI system is deployed without reliability engineering, it is prone to hallucinations—presenting false information with high confidence. In 2025, 59% of organizations listed “confidently wrong” AI configurations as a top security concern. If an AI agent managing cloud infrastructure hallucinates a network command, it can trigger cascading outages.
2. The Explosion of Security Risks
AI-related security and privacy incidents rose by 56.4% between 2023 and 2024. A major vulnerability in unreliable AI systems is “secrets leakage,” where an AI inadvertently exposes sensitive credentials, API keys, or long-lived tokens in its output logs.
3. The ROI Reality Check
Despite immense capital expenditure, the financial payoff is heavily delayed for organizations lacking engineering maturity. Global spending on AI is projected to hit massive figures, yet a 2026 PwC CEO survey covering over 4,400 global executives revealed that 56% of CEOs have seen neither revenue gains nor cost savings from AI. Achieving ROI requires long-term operational reliability; data shows most successful organizations achieve satisfactory ROI within 2 to 4 years, not months.
Traditional Software Engineering vs. AI Solution Engineering
To grasp AI engineering, you must first unlearn some principles of traditional software development. Traditional code is deterministic: if X happens, do Y. AI is probabilistic: given X, there is an 85% chance the answer is Y.
This fundamental difference changes how systems are built, tested, and maintained.
| Feature | Traditional Software Engineering | Reliable AI Solution Engineering |
| Core Logic | Deterministic (Rules are explicitly written by human programmers). | Probabilistic (Rules are inferred by algorithms from training data). |
| Primary Artifacts | Source Code and compiled binaries. | Code, massive datasets, and mathematical Model Weights. |
| Testing Focus | Unit, integration, and end-to-end testing focused on logic bugs and edge cases. | Model evaluation, bias testing, hallucination checks, and statistical benchmarking. |
| System Degradation | Software does not “decay” unless the underlying hardware or OS changes. | Models actively decay over time due to Data Drift and Concept Drift (changes in real-world data). |
| Maintenance | Bug fixes, feature updates, and security patching. | Continuous retraining, data pipeline monitoring, and MLOps lifecycle management. |
| Security Risks | Code vulnerabilities (e.g., SQL injection, buffer overflows). | Data poisoning, prompt injection, model inversion, and data leakage. |
The Pillars of Reliable AI Solution Engineering
Building a trustworthy AI system requires a multi-disciplinary approach resting on four foundational pillars.
1. Robust Data Foundation (Data Engineering)
AI is only as reliable as the data it consumes. Reliable AI engineering requires robust data pipelines that ingest, clean, validate, and store data efficiently. This involves managing structured databases, unstructured data lakes, and vector databases used for Retrieval-Augmented Generation (RAG). If the data pipeline breaks, or if toxic data enters the system, the AI model will fail.
2. Scalable Model Operations (MLOps & LLMOps)
Machine Learning Operations (MLOps) and Large Language Model Operations (LLMOps) are the backbone of AI reliability. This pillar focuses on version-controlling models, automating the training and deployment processes, and continuously monitoring models in production. A reliable MLOps pipeline ensures that if a model starts giving inaccurate predictions, the system automatically flags it, reverts to an older stable version, or triggers a retraining cycle.
3. Security, Privacy, and Guardrails (AI Trust)
Reliable AI engineering assumes the model will eventually try to do something wrong. Therefore, engineers build strict guardrails around the model. This includes input/output filtering (to stop malicious prompts or toxic responses), Role-Based Access Control (RBAC), and strict adherence to the Principle of Least Privilege. In fact, recent 2026 infrastructure data shows that organizations applying least-privileged access to AI systems decrease their incident rates by a staggering 4.5x compared to those with over-privileged AI.
4. Human-in-the-Loop (HITL) & Fallback Mechanisms
No AI system is 100% autonomous in a reliable enterprise setting. Engineering reliability means designing graceful degradation and fallback mechanisms. If the AI system is unsure of an answer (low confidence score), it should automatically route the query to a human operator rather than guessing.
The Lifecycle of Reliable AI Development
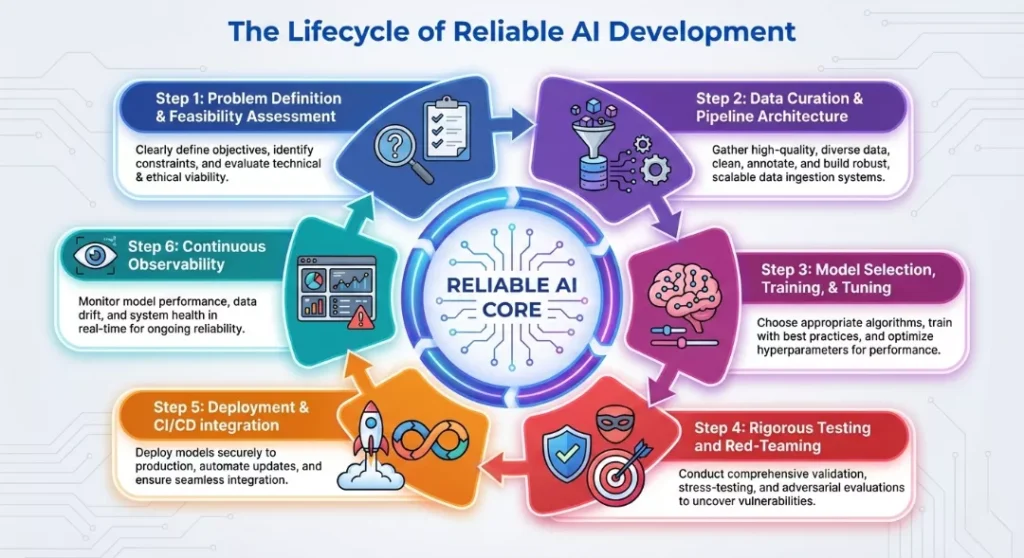
To operationalize the pillars above, AI engineers follow a strict, iterative lifecycle.
Step 1: Problem Definition & Feasibility Assessment
Not every problem requires AI. Reliable engineering starts with questioning if a simpler heuristic or traditional code could solve the issue. If AI is necessary, engineers define strict success metrics (e.g., latency, accuracy, cost-per-query).
Step 2: Data Curation & Pipeline Architecture
Engineers establish automated data pipelines to gather and preprocess training or context data. In the age of Generative AI, this often means chunking enterprise documents, creating embeddings, and storing them in vector databases for RAG architectures.
Step 3: Model Selection, Training, & Tuning
Rather than building models from scratch, reliable AI engineering often involves selecting the right foundational model (open-source like Llama or proprietary like Gemini) and fine-tuning it. Engineers balance the trade-offs between model size, inference speed, and compute costs.
Step 4: Rigorous Testing and Red-Teaming
Before deployment, the AI undergoes “red-teaming”—where security engineers intentionally try to break the model, bypass its safety filters, or force it to hallucinate. The model is also tested for inherent biases to ensure fair and equitable outcomes.
Step 5: Deployment & CI/CD integration
The model is wrapped in an API and deployed using Continuous Integration/Continuous Deployment (CI/CD) practices. Deployment strategies like “Canary Releases” (rolling the AI out to just 5% of users first) are used to mitigate risk.
Step 6: Continuous Observability
Once live, the work has just begun. Engineers use observability tools to monitor API latency, compute costs, and statistical drift. If the real-world data begins to look different from the training data, alerts are fired to the engineering team.
Key Roles in the AI Engineering Ecosystem
The demand for reliable AI has triggered a massive shift in the tech labor market. Legacy roles are evolving, and new specializations are emerging to handle the complexities of AI at scale.
- AI Engineers / ML Engineers: The core builders who design, train, and optimize machine learning models and LLMs. They bridge the gap between pure data science and software engineering.
- Forward-Deployed AI Engineers: These professionals work directly on the front lines with clients (e.g., hospitals, banks) to integrate AI solutions directly into highly specific, complex legacy workflows.
- Agentic Workflow Architects: A rapidly growing role for 2026. These architects design autonomous “AI Workers” or agents that can handle entire end-to-end business processes (like supply chain tracking) with minimal human oversight.
- AI Forensic Analysts: Security and compliance specialists who monitor AI systems for bias, safety, and traceability. They reconstruct AI decision-making timelines to understand why a model made a specific (sometimes erroneous) choice.
- Data Annotators: The human workforce that labels, scores, and structures data to train models, often providing the crucial Reinforcement Learning from Human Feedback (RLHF) that makes modern AI aligned and safe.
Current Market Landscape & 2026 Statistics
The economic footprint of AI engineering is expanding at an unprecedented rate, but it is heavily bottlenecked by a global talent shortage and the inherent complexities of enterprise integration.
- Market Growth: The global artificial intelligence engineering market was valued at roughly $12.65 billion in 2024. It is projected to hit $17.41 billion in 2025 and skyrocket to approximately $281.47 billion by 2034, growing at a staggering CAGR of over 36%.
- The Skills Deficit: The demand for AI engineering talent far outpaces supply. In the U.S. alone, there are an estimated 1.3 million AI job openings over the next two years, but a qualified talent pool of fewer than 645,000. Similarly, India—despite having the highest number of AI learners globally—faces a 50-55% talent gap for production-ready AI engineers.
- Shift to Build vs. Buy: Interestingly, data reveals a significant divide in success based on how organizations source their AI. Vendor-purchased AI tools and platforms succeed roughly 67% of the time, while internally built, custom solutions succeed only 33% of the time. This highlights the sheer difficulty of building reliable AI infrastructure from scratch.
Common Pitfalls and How to Avoid Them
Even with the best intentions, organizations frequently stumble when trying to implement AI solutions. Here are the most common pitfalls and how reliable engineering practices solve them.
1. Neglecting Organizational Change Management
AI is not just an IT project; it is a business transformation project. A major reason 42% of projects are abandoned is due to implementation complexity and user resistance. Solution: Involve end-users early in the lifecycle and ensure the AI tool fits seamlessly into their existing daily workflows rather than forcing them to learn entirely new behaviors.
2. Over-Privileged AI Agents
Giving an AI agent administrative access to databases or cloud infrastructure is a recipe for disaster. Solution: Implement strict Identity and Access Management (IAM) for AI. Treat AI agents like third-party contractors—give them the absolute minimum permissions necessary to complete their specific task.
3. Ignoring Data Quality for Model Sophistication
Many teams spend weeks tweaking prompts or switching between the latest LLMs, while ignoring the fact that their underlying company data is messy, outdated, or siloed. Solution: Shift focus to Data-Centric AI. Invest 80% of your effort into cleaning, structuring, and maintaining high-quality data pipelines. A mediocre model with excellent data will always outperform a state-of-the-art model with garbage data.
The Future of AI Solution Engineering
As we look toward the end of the decade, Reliable AI Solution Engineering will become less about deploying single chatbots and more about managing ecosystems of autonomous agents.
Gartner predicts that by the end of 2026, 40% of enterprise applications will integrate task-specific AI agents. This “Agentic AI” wave means engineers will need to focus heavily on multi-agent orchestration—ensuring that different AI systems can talk to each other safely, negotiate tasks, and hand off errors without human intervention.
Furthermore, regulatory compliance is shifting from a legal afterthought to a hard engineering constraint. With governments worldwide rolling out stringent AI acts, reliable AI engineering will legally require deep explainability, audit trails, and proven safety guardrails built directly into the codebase.
Conclusion
Artificial intelligence is no longer a futuristic concept; it is a present-day infrastructure challenge. What is reliable AI solution engineering? It is the uncompromising discipline that turns the chaotic, probabilistic nature of machine learning into a stable, secure, and profitable business asset. By prioritizing robust data foundations, strict MLOps lifecycles, and relentless security testing, organizations can avoid pilot paralysis and build AI systems that truly scale.
The era of AI experimentation is over. The era of AI industrialization and engineering has begun.