
On-device inference is the process of running pre-trained artificial intelligence models directly on a local hardware device—such as your smartphone, laptop, or a smart home sensor—rather than sending your data to a remote cloud server for processing. When you use Face ID to unlock your phone, dictate a text message in an area with no signal, or use an AI tool to blur your background during a video call, you are witnessing on-device inference in action. By keeping the “thinking” process local, your device provides near-instant responses, protects your personal privacy by keeping data on-site, and functions perfectly even when you are completely offline.
The “Thinking” vs. “Learning” Divide: What Is Inference?
To understand on-device inference, we first need to clear up a common confusion: the difference between AI Training and AI Inference.
Think of AI Training like a medical student spending eight years in university. They consume massive amounts of textbooks, attend lectures, and take exams to build a “brain” full of knowledge. This process is computationally expensive, requires giant “libraries” (data centers), and takes a long time.
Inference, on the other hand, is when that doctor walks into a clinic and diagnoses a patient based on what they already know. They aren’t “learning” a new branch of medicine from scratch; they are simply applying their existing knowledge to a new, specific situation. In AI terms, inference is the moment the model takes an input (like your voice) and produces an output (like a translated sentence).
Historically, because AI models were massive and required huge amounts of “brainpower,” we had to send our questions to the “university” (the cloud) to get an answer. But in 2026, our devices have become smart enough to carry the doctor around in their pocket.
Why the Shift? Cloud Inference vs. On-Device Inference
For the last decade, we lived in a “Cloud-First” world. If you asked a voice assistant a question, your voice was recorded, compressed, sent over the internet to a data center, processed by a giant GPU, and the answer was sent back. This worked, but it had three major “glitches”:
- Latency: Even with 5G, the “round-trip” to the cloud takes time. For things like self-driving cars or augmented reality, a 200-millisecond delay isn’t just annoying—it’s dangerous.
- Privacy: To get an AI answer, you had to share your data. Whether it was a photo of your family or a sensitive work document, it had to leave your possession.
- Cost and Energy: Moving billions of data packets across the globe every day is incredibly expensive for companies and consumes a staggering amount of electricity and water for cooling data centers.
On-device inference flips the script. By performing the math locally, we eliminate the commute. It’s the difference between driving to a library to look up a word and having the dictionary already open on your desk.
The Hardware: The Secret Sauce of 2026 Devices
You might be wondering: “How can my thin smartphone do the same math as a giant server?” The answer lies in specialized hardware called the NPU (Neural Processing Unit).
1. The Neural Processing Unit (NPU)
An NPU doesn’t care about running your Excel spreadsheet or rendering a 3D game. It only cares about flowing data through a neural network as efficiently as possible. In 2026, chips like the Snapdragon 8 Elite Gen 5 or the Apple A19 Pro have NPUs capable of over 60 TOPS (Trillions of Operations Per Second). To put that in perspective, your phone now has more AI “muscle” than a high-end desktop computer from just a few years ago.
2. The Memory Bottleneck
If the NPU is the engine, the RAM is the fuel line. The biggest challenge for on-device inference isn’t the speed of the processor—it’s how fast we can move the AI model’s “weights” (its knowledge) from the memory to the processor.
In a data center, GPUs have massive “high-bandwidth memory.” On a phone, we have to be more creative. This is why 2026 smartphones are shipping with specialized LPDDR5X-SOCAMM memory, which acts like a high-speed carpool lane for AI data, ensuring the NPU never sits idle waiting for information.
Software Magic: How We Shrink the Giants
You can’t fit a grand piano into a suitcase without some serious disassembly. Similarly, you can’t fit a 175-billion parameter model like GPT-4 onto a smartphone without “Software Optimization.” Engineers use three main tricks to make this happen:
1. Quantization: The Art of Rounding Down
In a laboratory, AI models use high-precision numbers (FP32). This is like measuring a table down to the width of a human hair. For on-device use, we don’t need that much detail. Quantization converts these complex numbers into simple integers (like INT8 or even INT4).
Technically, the formula for a basic linear quantization looks like this:
Wq=round(SW+Z)
Where:
- W is the original weight.
- S is the scale factor.
- Z is the zero-point.
By “rounding” the math, we can shrink a model’s size by 4x or 8x with almost no noticeable drop in intelligence. It’s like switching from a 4K video to 1080p—it still looks great, but the file is much smaller.
2. Pruning: Trimming the Fat
During training, an AI model develops millions of “neurons” that don’t actually do much. Pruning is the process of identifying these useless connections and cutting them out. It’s like an editor taking a 500-page manuscript and realizing they can tell the same story in 200 pages by removing the “fluff.”
3. Knowledge Distillation
This is my favorite one. You take a “Teacher” model (a giant AI) and let it train a “Student” model (a tiny AI). The student doesn’t learn everything; it just learns how to mimic the teacher’s answers for specific tasks. The result is a “Small Language Model” (SLM) that is light enough to run on a watch but smart enough to handle your daily emails.
The 5 Game-Changing Benefits of On-Device AI
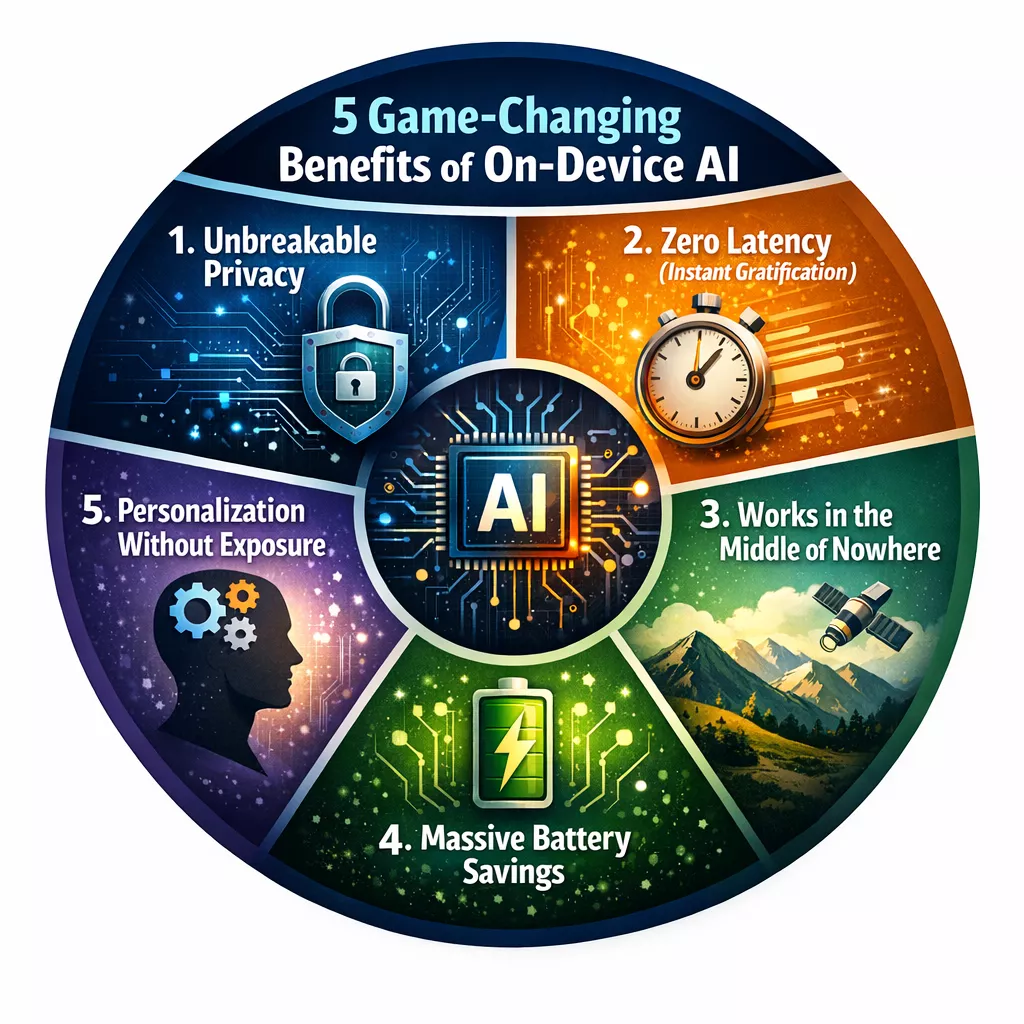
Why should you care if the AI is on your device or in the cloud? Because it changes your daily life in five specific ways:
1. Unbreakable Privacy
In a world of data breaches, on-device inference is the ultimate shield. When you use an AI health app to analyze a skin rash or a financial AI to track your spending, that sensitive information never leaves your device. There is no “middleman” server that could be hacked. If the data isn’t transmitted, it can’t be stolen in transit.
2. Zero Latency (Instant Gratification)
Have you ever used a voice assistant and waited three seconds for it to say “Searching…”? That’s cloud latency. On-device inference happens in milliseconds. This is critical for Real-Time Translation. Imagine wearing AI glasses that translate a foreign street sign the moment you look at it. If that had to go to the cloud, you’d have walked past the sign before the translation appeared.
3. Works in the Middle of Nowhere
Cloud AI is useless in an airplane, a subway, or a remote hiking trail. On-device AI doesn’t care about your bars or your Wi-Fi password. It is Offline-First. This makes it an essential tool for field workers, travelers, and anyone living in areas with spotty connectivity.
4. Massive Battery Savings
It sounds counter-intuitive—doesn’t running math on my phone drain the battery? Actually, sending data over a 5G or Wi-Fi radio is one of the most power-hungry things a phone can do. Recent studies in 2025/2026 showed that running a query on a local NPU can use up to 90% less energy than the total energy required to package, send, and receive that same data from a cloud server.
5. Personalization Without Exposure
Because the AI lives on your device, it can “learn” your specific habits—the way you talk, your favorite coffee shop, your work schedule—without ever sharing that profile with a big tech company. It becomes a Personal AI that knows you deeply but keeps your secrets.
Real-World Applications: Where You’ll See It in 2026
On-device inference isn’t just a tech spec; it’s the engine behind the most exciting features of 2026.
| Industry | On-Device AI Application |
| Photography | Real-time “Generative Fill” and low-light denoising using local diffusion models. |
| Healthcare | Wearables that detect heart arrhythmias or seizure patterns locally for instant alerts. |
| Productivity | “Copilot” features on PCs that summarize long documents and write code without an internet connection. |
| Gaming | AI-driven NPCs (Non-Player Characters) that have unscripted, natural conversations with you in real-time. |
| Accessibility | Live captions and “Personal Voice” generation for users with speech or hearing impairments. |
| Smart Home | Security cameras that recognize “Stranger vs. Friend” locally, so your video feed stays private. |
The Challenges: It’s Not All Sunshine and Rainbows
While we’ve made incredible progress, on-device inference still faces some “Final Boss” hurdles:
- Thermal Management: If you run a massive AI model for too long, your phone will get hot. When a device gets too hot, it “throttles” (slows down) to protect the hardware. Engineers in 2026 are still working on better “heat sinks” and “vapor chambers” for mobile devices.
- The Model Size Limit: We can’t fit everything on a phone. While we can run a 3-billion parameter model locally, a 1-trillion parameter model still needs the cloud. This is leading to a Hybrid AI approach: your phone handles the easy stuff, and only calls the cloud for the “Einstein-level” problems.+1
- Memory Prices: As we demand more RAM for AI, the cost of smartphones and laptops is creeping up. In 2026, “AI-Ready” usually means a premium price tag.
Looking Ahead: The Future is “Small”
The biggest trend of 2026 isn’t “Bigger AI,” it’s “Smarter Small AI.” We are seeing a massive wave of Small Language Models (SLMs) like Gemma 3 and Llama 3.2. These models are proving that you don’t need a billion-dollar data center to be helpful.
We are also seeing the rise of Federated Learning. This is a futuristic concept where your device does its own inference, learns a little bit about how to be better, and then shares only the learning (not the data) with a central hub. This allows the AI to get smarter for everyone without anyone ever losing their privacy.
Conclusion: Your Device is Finally Growing a Brain
For years, our devices were just “windows” into the internet. Without a connection, they were basically expensive paperweights. On-device inference has changed that. It has given our phones, watches, and laptops their own “local intelligence.”
As we move deeper into 2026, the line between “online” and “offline” will continue to blur. You won’t ask, “Is this AI connected?” You’ll just expect it to work—instantly, privately, and reliably. On-device inference is the “invisible” technology making the AI revolution personal.