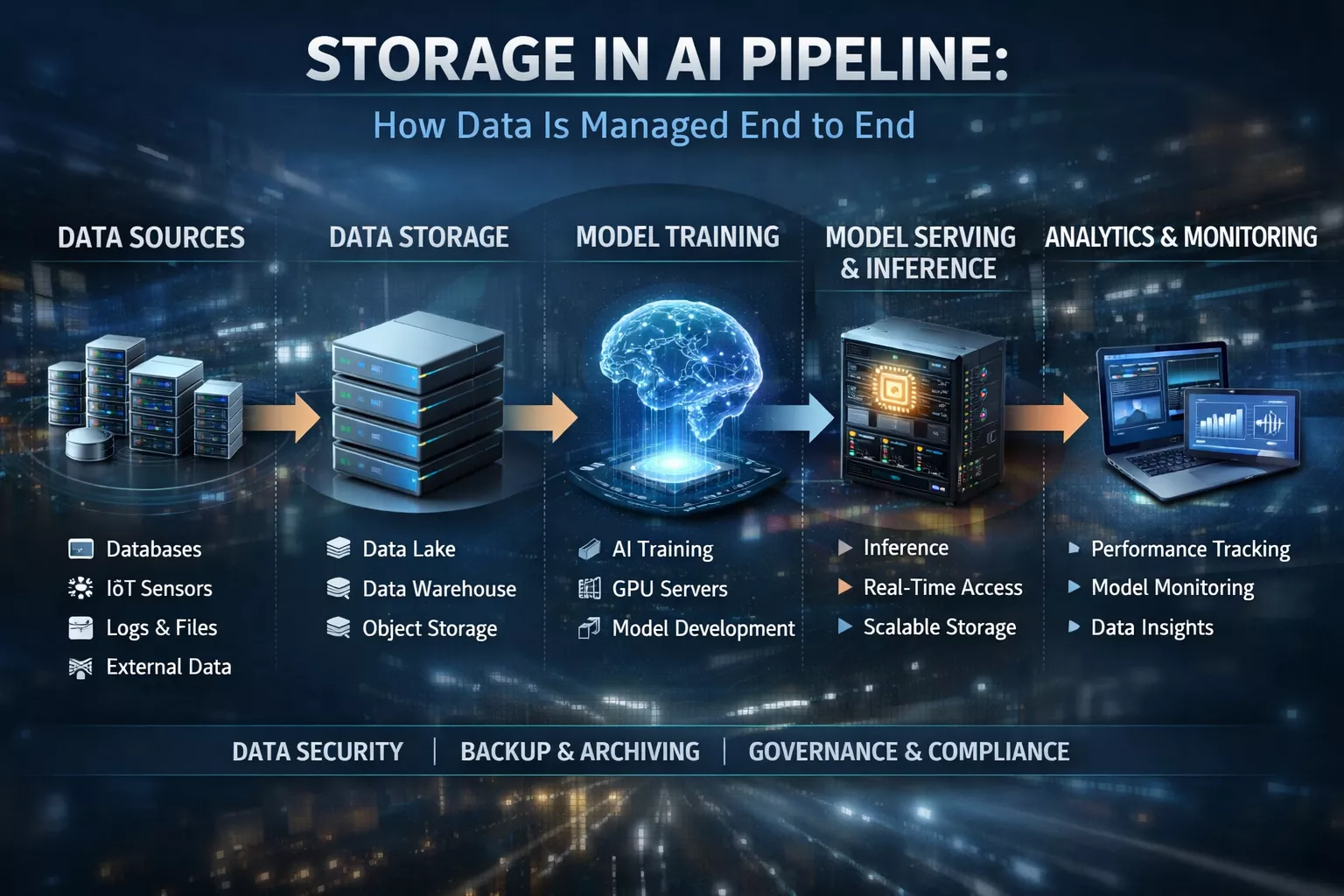
Storage in an AI pipeline serves as the specialized data infrastructure that actively manages information’s lifecycle, from initial ingestion through model training and onto final inference. Unlike traditional storage, this system must simultaneously handle massive capacity for raw data lakes – such as petabytes of unstructured video, text, or audio – while providing extreme performance to feed data into GPUs. Furthermore, it must deliver high throughput and low latency to prevent computational bottlenecks. Effective AI storage orchestrates this flow by tiering data; specifically, it moves files from cost-effective, high-capacity object storage for archiving to high-speed NVMe or parallel file systems for active processing. Consequently, this ensures that expensive compute resources never remain idle while waiting for data.
The Unsung Hero of the AI Revolution
When people discuss the current AI explosion, the spotlight almost always lands on the “brains” of the operation: the GPUs, the TPUs, and massive neural network architectures like Transformers. We marvel at the speed of computation and the parameter counts. However, a silent, critical partner exists in this dance, one that often goes unnoticed until it fails: Storage.
Think of an AI model as a high-performance Formula 1 car. The GPU acts as the engine, capable of incredible speed. Conversely, storage functions as the fuel line. If that fuel line creates friction or fails to pump fuel (data) fast enough, the engine’s power becomes irrelevant; the car will simply stall. In the world of Artificial Intelligence, while data represents the new oil, storage acts as the pipeline that actively refines, transports, and delivers that oil.
Moreover, managing data end-to-end in an AI pipeline involves more than just providing “enough space.” In reality, it presents a complex engineering challenge. Teams must move petabytes of data across different hardware tiers, optimize for varying read/write patterns, and balance the astronomical costs of high-speed flash memory against slower, cheaper archival disks.
The AI Data Lifecycle: A Stage-by-Stage Breakdown
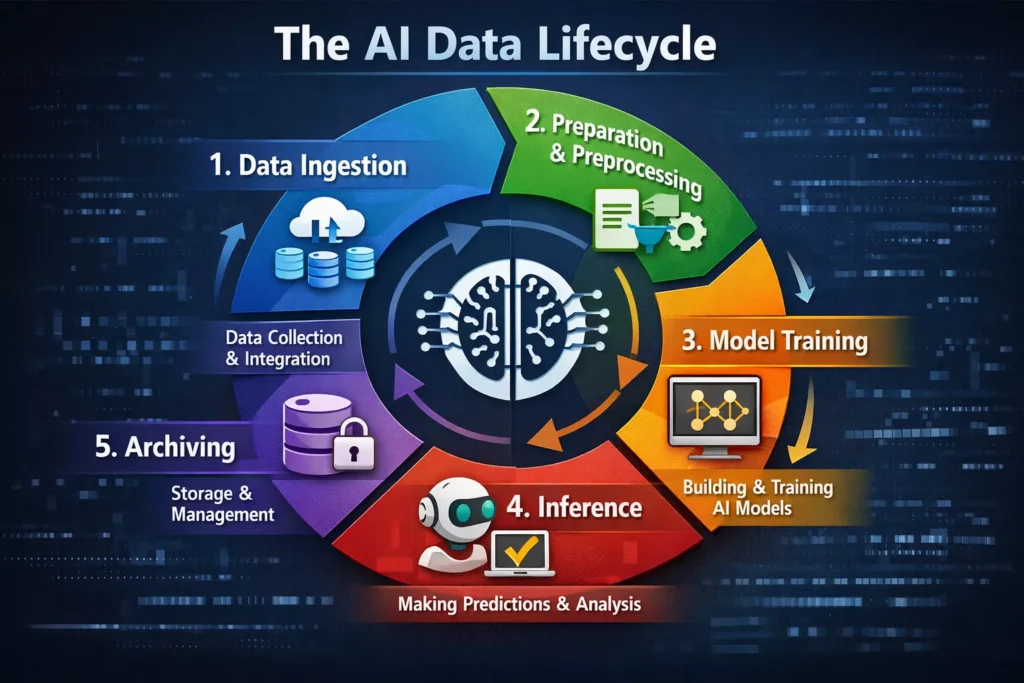
To understand how engineers manage data, we must look at the pipeline linearly. Specifically, each stage of AI development places a radically different demand on storage infrastructure.
1. Data Ingestion: The Infinite Lake
The journey begins with Ingestion. At this point, raw data flows into the system from the real world.
- The Data Source: IoT sensors, web scrapers, satellite feeds, or user logs.
- The Storage Challenge: The primary requirement here involves Write Throughput and Scalability. The system must actively accept a firehose of incoming data without dropping a single packet.
- The Solution: Consequently, architects typically choose Object Storage (like Amazon S3 or on-premise equivalents like MinIO). Object storage scales infinitely by design. It ignores complex folder hierarchies; instead, it simply takes a piece of data (an object), assigns it a unique ID, and deposits it into the “lake.”
- Human Analogy: Imagine a library receiving donations. During this stage, librarians are not shelving books alphabetically; rather, they are dumping boxes into a massive warehouse as fast as the trucks arrive.
2. Preparation and Preprocessing: The Refinery
Once the data settles in the lake, it usually appears messy. Images differ in size; text contains weird encoding; audio files possess background noise.
- The Task: Cleaning, labeling, normalization, and transformation (ETL).
- The Storage Challenge: This stage involves a mix of sequential and random reads/writes. Systems need to open a file, modify it, and save it back. As a result, this causes “IOPS storms” (Input/Output Operations Per Second). Traditional hard drives (HDDs) often choke here because the read/write head must physically move to find data scattered across the disk.
- The Solution: Therefore, engineers often move data from the “Cold” object storage to a “Warm” tier, often powered by Standard SSDs. Here, data scientists might use distributed file systems (like HDFS) to process massive datasets in parallel.
3. Model Training: The Racetrack
Undoubtedly, this represents the most critical and expensive phase.
- The Task: Feeding the cleaned data into the GPU for training. The model iterates over the data (epochs) thousands of times to learn patterns.
- The Storage Challenge: Read Latency and Bandwidth. Modern GPUs (like the NVIDIA H100) operate incredibly fast. If the storage fails to deliver data batches instantly, the GPU sits idle. Experts call this “GPU Starvation,” and considering these chips cost tens of thousands of dollars, idle time effectively burns money.
- The Solution: This scenario requires the “Hot” tier. We are referring to All-Flash Arrays and NVMe (Non-Volatile Memory Express) storage.
- Parallel File Systems: Organizations utilize technologies like Lustre, GPFS (IBM Spectrum Scale), or WEKA. Unlike standard file systems that queue requests one by one, parallel file systems break a single file into chunks and serve them from multiple servers simultaneously. Thus, they saturate the network link to the GPU.
- Caching: Often, the dataset exceeds the GPU’s RAM (VRAM) capacity, so the system must stream it from storage. Intelligent caching algorithms predict which data chunk the GPU will need next and preload it.
4. Inference: The Delivery
After the team trains the model, it enters production to make predictions.
- The Task: A user asks ChatGPT a question, or a self-driving car spots a stop sign.
- The Storage Challenge: Low Latency for Random Reads. Unlike training (which reads massive batches of data sequentially), inference operates randomly. One user asks about cats; the next asks about quantum physics. Consequently, the model needs to access its weights and parameters instantly.
- The Solution: Typically, high-performance local NVMe SSDs function right at the “Edge” (e.g., inside the car or the edge server). For Large Language Models (LLMs), the system often loads the entire model into memory (RAM/VRAM), yet the storage must remain fast enough to load the model quickly upon system startup (hydration).
5. Archiving: The Vault
Data that the system has processed and no longer needs for active training does not simply disappear. Instead, it creates a “Data Gravity” problem.
- The Task: Compliance, audit trails, and future re-training.
- The Storage Challenge: Cost. Storing petabytes on high-speed NVMe remains financially impossible.
- The Solution: Tape drives (LTO) and Cold Cloud Storage (like AWS Glacier). Surprisingly, tape remains alive and well in 2024-2026 because it consumes zero electricity when sitting on a shelf. Additionally, it is immune to ransomware since it stays offline (air-gapped).
Critical Technologies Defining AI Storage
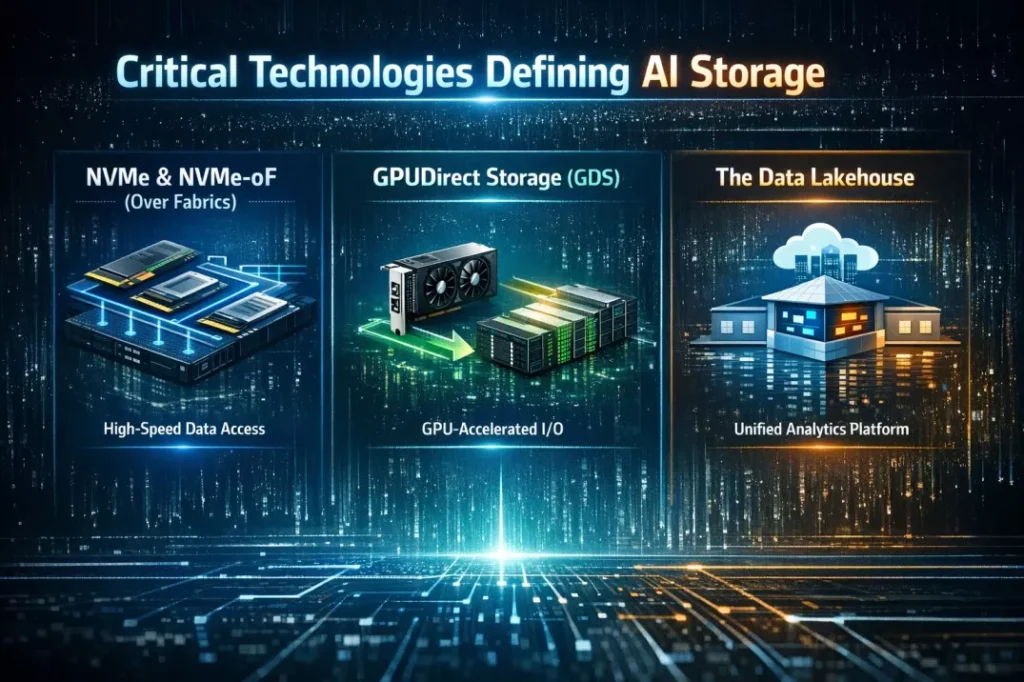
To manage this complex pipeline effectively, several specific technologies have risen to prominence.
NVMe and NVMe-oF (Over Fabrics)
Engineers designed old storage protocols (SATA/SAS) for spinning hard drives. In contrast, they designed NVMe specifically for flash memory. It allows thousands of parallel queues of commands. Furthermore, NVMe-oF takes this a step further; it allows a GPU to access storage across a network with the same speed as if someone plugged the drive directly into the server. This decouples storage from compute, which allows teams to scale them independently.
GPUDirect Storage (GDS)
Traditionally, when data moves from storage to a GPU, it must go through the CPU and the system memory (RAM) first. Unfortunately, this creates a bottleneck (the “CPU bounce”). To solve this, GPUDirect Storage allows the storage drive to send data directly to the GPU memory, bypassing the CPU entirely. Consequently, this significantly lowers latency and frees up the CPU for other tasks.
The Data Lakehouse
This represents a modern architectural shift. Historically, companies maintained “Data Lakes” for raw files and “Data Warehouses” for structured, analytics-ready data. However, AI needs both. The Lakehouse architecture combines the cheap storage of a lake with the management features (ACID transactions, schema enforcement) of a warehouse, effectively preventing data silos.
Current Statistics in AI Storage (2024-2026)
The growth of AI drives a parallel explosion in the storage market. Specifically, the sheer volume of data required to train Generative AI models reshapes the industry.
| Metric | Statistic | Source/Context |
| Global Data Creation | 181 Zettabytes by end of 2025 | Projected total global data volume (Statista/IDC). |
| AI Storage Market Size | $76.6 Billion by 2030 | Projected growth from ~$20-30B in 2024 (Mordor Intelligence). |
| Market CAGR | ~23% – 25.9% (2025-2030) | Compound Annual Growth Rate for AI-powered storage. |
| Unstructured Data | >80% of enterprise data | The vast majority of data used for AI is unstructured (video, text, audio). |
| Storage Spend | ~40% of AI Infrastructure Cost | A significant portion of AI budgets goes to storage and memory, not just compute. |
Challenges in End-to-End Management

Even with advanced tech, managing this pipeline presents significant headaches.
1. The “Data Gravity” Problem
As datasets grow to petabytes, they become “heavy.” For example, moving 1 Petabyte of data from a cloud in the US to a cloud in Europe can take weeks or months over standard networks. Additionally, it costs a fortune in egress fees. Therefore, this forces compute to move to the data, rather than vice versa, which complicates architecture.
2. The Checkpoint Bottleneck
During training, models must save their progress periodically (checkpointing). This ensures that if the system crashes, the team does not lose weeks of work. However, these checkpoints can reach hundreds of gigabytes in size. Pausing training to write this file to disk wastes valuable GPU time. Thus, modern storage must handle “bursty” write traffic to save checkpoints instantly.
3. Security and Compliance
AI pipelines often ingest sensitive data (PII, healthcare records). Moreover, “Poisoning” attacks—where hackers insert malicious data into the training set to corrupt the model—represent a new threat. Consequently, storage systems now require immutable snapshots (WORM – Write Once, Read Many) to ensure no one has tampered with training data.
Future Trends: What’s Next?
CXL (Compute Express Link)
CXL is an emerging interconnect standard that allows different processors (CPU, GPU) to share a pool of memory. Looking ahead, “Memory-Semantic SSDs” using CXL could blur the line between RAM and Storage, offering massive capacities at near-DRAM speeds.
DNA Storage
While still in R&D, the explosive growth of data may eventually force us toward biological storage. DNA can store massive amounts of data in microscopic volumes for thousands of years. Ultimately, it serves as the ideal “Cold” storage solution for the zettabyte era.
Hybrid Cloud “Bursting”
Increasingly, more companies are adopting a hybrid approach. They keep sensitive data and steady-state training on-premise (to save costs) but “burst” to the public cloud for temporary storage and compute during intense training runs.
Conclusion
Storage no longer acts as a passive warehouse for digital bits; rather, it functions as an active, intelligent participant in the AI pipeline. As models grow from billions to trillions of parameters, the bottleneck shifts from how fast we can calculate to how fast we can feed.
For any organization building an AI strategy, investing in GPUs without upgrading storage is akin to buying a Ferrari engine and installing it in a go-kart. Therefore, a robust, tiered, end-to-end storage strategy—leveraging Object Storage for scale and NVMe for speed—remains the only way to unlock the true potential of Artificial Intelligence.