
Small Language Models (SLMs) are streamlined artificial intelligence systems designed to perform natural language tasks with high efficiency, utilizing significantly fewer parameters—typically under 10 billion—compared to massive Large Language Models (LLMs). Unlike their trillion-parameter counterparts that rely on massive cloud servers, SLMs are optimized to run directly on laptops, smartphones, and edge devices, offering faster processing, enhanced data privacy, and lower operational costs without sacrificing capability for specific tasks.
Introduction: Why “Small” is the New Big in AI
For the past few years, the AI headline has been “Bigger is Better.” We watched models grow from billions to trillions of parameters, consuming enough electricity to power small cities. But in 2024 and 2025, the narrative shifted. The industry realized that while you need a massive semi-truck to move a house, you only need a bicycle to deliver a letter.
Enter Small Language Models (SLMs). These are the “bicycles” of the AI world—agile, efficient, and surprisingly capable. They are not trying to know everything about everything; instead, they are designed to be specialists, running locally on your phone or your company’s private server, handling tasks with speed and privacy that massive cloud models simply cannot match.
What Actually is a Small Language Model?
To understand SLMs, we first need to talk about parameters. In AI, parameters are roughly equivalent to the neural connections in a brain—they represent the “knowledge” the model has learned.
- LLMs (Large Language Models): Models like GPT-4 or Claude 3 Opus often have parameters in the trillions or high hundreds of billions. They are generalists—they know French poetry, Python coding, and 14th-century history.
- SLMs (Small Language Models): These typically have fewer than 10 billion parameters, with many efficient versions hovering around 3 billion to 7 billion.
Think of an LLM as a university professor who knows a little bit about everything. Think of an SLM as a specialized technician who has studied one manual perfectly. The technician may not know poetry, but they can fix the machine faster and cheaper than the professor.
How Do They Make Them “Smart” but Small?
SLMs aren’t just “dumber” versions of big models. They are created using advanced techniques to ensure they punch above their weight class:
- Distillation: This is like a teacher (a massive LLM) teaching a student (the SLM). The massive model generates the best possible answers, and the small model is trained to mimic those answers, learning the “reasoning” without needing the massive memory.
- Quantization: This process reduces the precision of the numbers used in the model (e.g., moving from high-definition 32-bit numbers to lower-res 4-bit numbers). It makes the model much smaller and faster with barely any loss in intelligence.
- High-Quality Training Data: Instead of feeding the model the entire chaotic internet, developers feed SLMs highly curated, “textbook-quality” data. As the saying goes in AI now: “Quality over Quantity.”
The Showdown: SLMs vs. LLMs
To help you decide which is right for your needs, here is a direct comparison.
| Feature | Large Language Models (LLMs) | Small Language Models (SLMs) |
| Parameter Size | 100B – 1Trillion+ | 0.5B – 10B |
| Deployment | Massive Cloud Servers (GPUs clusters) | Edge Devices (Laptops, Phones, IoT) |
| Cost to Run | High (e.g., $10-$30 per million tokens) | Ultra-Low (e.g., $0.10 per million tokens) |
| Privacy | Data usually leaves your device | Data stays on-device (Air-gapped) |
| Latency | Slower (network lag + processing) | Real-time / Instant |
| Best For | Complex reasoning, creative writing, general knowledge | Specific tasks, coding, summarization, privacy-heavy use |
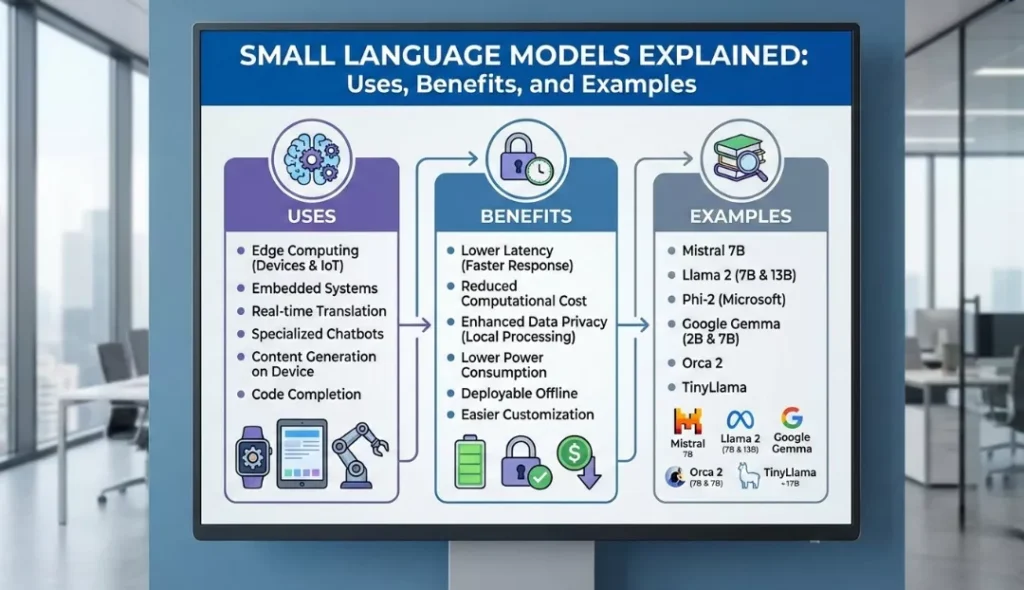
5 Key Benefits of Small Language Models
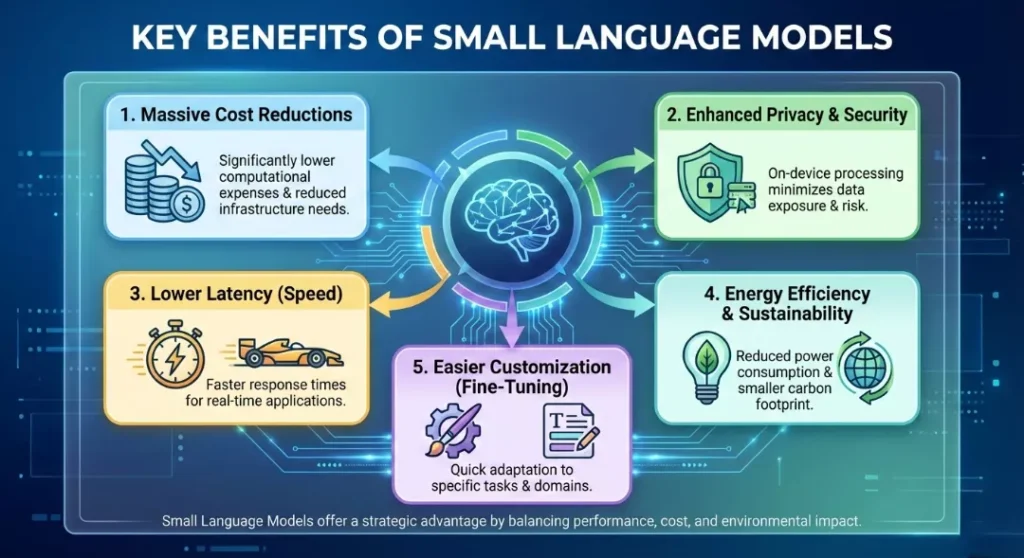
1. Massive Cost Reductions
Running a massive model is expensive. For enterprises, the cost of “inference” (asking the AI a question) can add up to millions annually. SLMs can reduce these costs by 10x to 100x. Because they are smaller, they require less computing power, meaning you don’t need expensive H100 GPU clusters to run them.
2. Enhanced Privacy and Security
This is the “killer app” for SLMs. Because they are small enough to run on a local device (like a laptop or a secure on-premise server), your data never has to leave the building.
- Example: A law firm can use an SLM to analyze confidential contracts without ever uploading that sensitive client data to a public cloud provider like OpenAI or Google.
3. Lower Latency (Speed)
When you chat with a cloud AI, your request travels to a data center, gets processed, and comes back. SLMs eliminate this network travel time. They generate tokens (text) much faster—often 150-300 tokens per second compared to the 50-100 typical of larger models. This makes them perfect for real-time voice assistants or autocomplete features.
4. Energy Efficiency & Sustainability
Training and running massive models has a massive carbon footprint. SLMs consume a fraction of the energy. As the world becomes more conscious of AI’s environmental impact, SLMs offer a “greener” path to intelligence.
5. Easier Customization (Fine-Tuning)
It is incredibly difficult and expensive to “retrain” a trillion-parameter model on your company’s data. However, an SLM can be fine-tuned on a specific dataset (like a medical textbook or a company’s repair manuals) in a matter of hours on a single GPU.
Top Examples of SLMs (2024-2025)
The market is exploding with high-performance small models. Here are the current leaders:
1. Microsoft Phi-3.5 Mini (3.8B Parameters)

- The Specialist: Microsoft has proven that size isn’t everything. Phi-3.5 is trained on “textbook quality” data and rivals models 10x its size in reasoning and math.
- Key Feature: It has a massive context window (128k tokens), meaning it can read a whole book and answer questions about it—all on your phone.
2. Google Gemma 2 (2B, 9B, and 27B)

- The Open Powerhouse: Built from the same research and technology as Google’s massive Gemini models. The 9B version is currently a favorite for developers because it offers incredible performance that fits on consumer-grade graphics cards.
- Key Feature: Exceptional performance in coding and logical reasoning benchmarks.
3. Meta Llama 3 (8B)

- The Industry Standard: When Meta released Llama 3, the 8B parameter version became the default “brain” for thousands of independent AI apps. It is versatile, uncensored (in some versions), and highly capable.
- Key Feature: A massive community of developers constantly improving and fine-tuning it.
4. Apple OpenELM / Apple Intelligence

- The On-Device King: Apple’s strategy relies entirely on SLMs running locally on iPhones. These models handle summarization, Siri requests, and photo editing without sending data to the cloud.
5. Mistral 7B

- The Trendsetter: This was the model that arguably started the “small but mighty” revolution. Despite being older than the others on this list, it remains a benchmark for efficiency.
Real-World Use Cases: Where SLMs Shine
- Healthcare: Doctors can use an SLM fine-tuned on medical journals to summarize patient notes directly on a hospital tablet. Since the data never hits the internet, patient privacy (HIPAA) is maintained.
- Coding Assistants: Developers use SLMs integrated into their code editors (like VS Code) to autocomplete code. These models run locally, so proprietary company code isn’t leaked.
- IoT and Automotive: Modern cars are integrating SLMs to power voice assistants. You can ask your car, “What does this warning light mean?” and the car’s onboard computer answers instantly without needing a cell signal.
- Smartphones: Features like “Summarize this email” or “Suggest a reply” on modern Android and iOS devices are powered by SLMs running in the background.
Recent Market Statistics (2025 Outlook)
- Market Growth: The global SLM market was valued at approximately $7 billion in 2024 and is projected to skyrocket to over $58 billion by 2034, growing at a CAGR of nearly 24%.
- Adoption: Gartner and other analysts predict that by 2026, 50% of enterprise AI deployments will involve SLMs or specialized models rather than just generic giant models, driven by cost and privacy concerns.
- Cost Efficiency: Enterprises switching from GPT-4 to specialized SLMs for specific tasks (like document classification) report cost savings of up to 90%.
The Future: A Hybrid Approach
We are not moving toward a world of only small models. The future is Hybrid AI.
Imagine a system where an SLM lives on your phone. It handles 80% of your daily request—setting alarms, summarizing texts, finding files. But when you ask a complex question like, “Plan a 2-week itinerary for Japan including historical context of the Edo period,” the SLM recognizes it’s too difficult. It then “calls up” to a massive cloud LLM, gets the answer, and delivers it to you.
This orchestration between the fast, cheap edge (SLM) and the smart, expensive cloud (LLM) is the architecture of the future.
Conclusion
Small Language Models prove that in the world of AI, you don’t always need a supercomputer to solve a problem. By focusing on efficiency, privacy, and specialized training, SLMs are democratizing AI, making it accessible to run on the devices we use every day. Whether you are a business leader looking to cut costs or a developer building the next great app, it’s time to start thinking small.
Frequently Asked Questions (FAQs)
1. Can I run a Small Language Model on my personal laptop?
Yes, absolutely. This is one of the main advantages of SLMs. Most modern laptops with a decent amount of RAM (8GB or 16GB) can easily run models like Llama 3 (8B) or Microsoft Phi-3. If you have a laptop with a dedicated GPU (like an NVIDIA RTX series) or a Mac with an M1/M2/M3 chip, the performance will be incredibly fast. Tools like LM Studio or Ollama make downloading and running these models as easy as installing a regular app.
2. Do Small Language Models hallucinate less than massive models?
Not necessarily. While SLMs are highly efficient, they are essentially “compressed” knowledge. Because they have fewer parameters, they might struggle with obscure facts or complex logic puzzles, potentially leading to hallucinations (making things up) if pushed beyond their training limits. However, because they are easier to fine-tune on specific data (like your company’s documents), they can be more accurate for specialized tasks than a general-purpose giant model.
3. Will Small Language Models replace giant models like GPT-4?
No, they will likely work together. Think of it like vehicles: bicycles didn’t replace semi-trucks. We still need massive models (LLMs) for complex reasoning, scientific discovery, and handling ambiguous tasks. SLMs will take over the day-to-day, repetitive, and privacy-sensitive tasks, while the giant models will serve as “super-brains” for difficult problems.
4. Is my data 100% safe if I use a local SLM?
It is significantly safer than using cloud AI. When you run an SLM locally (on your own device), your data effectively never leaves your hardware. You can even run these models while your computer is in “Airplane Mode” (offline). This eliminates the risk of a third-party AI company using your private chats or documents to train their future models.
5. Are Small Language Models free to use?
Many of the best ones are. Models like Meta’s Llama series, Mistral, and Google’s Gemma are “open weights” models. This means developers and individuals can download and use them for free. However, while the model is free, if you deploy it for a huge app with millions of users, you will still have to pay for the electricity and hardware to run it.