
Neural networks power many of today’s most advanced AI systems—from ChatGPT and autonomous vehicles to medical imaging tools, recommendation engines, and fraud detection platforms. Despite their huge influence, most people still find the idea of neural networks confusing or overly technical. Their learning process often seems mathematical, abstract, or even mysterious.
In reality, neural networks learn through a simple cycle of trial and improvement. They process input data, make a prediction, compare that prediction to the correct answer, calculate how far off they were, and then adjust their internal parameters—known as weights and biases—to reduce future errors. This corrective process, called backpropagation, repeats thousands or even millions of times until the network becomes highly accurate.
In the sections ahead, we’ll break down this learning process in a clear, visual, and easy-to-understand way—so anyone can grasp how neural networks truly learn.
Why Neural Networks Matter Today
Neural networks are the backbone of nearly every advanced AI system we use today—ChatGPT, autonomous cars, facial recognition, medical diagnosis tools, search engines, voice assistants, fraud detection, and more.
But despite their growing influence, most people have no idea how they actually learn.
This guide explains neural networks from the ground up—no PhD required.
You’ll learn:
- What neural networks are
- How they think
- How they learn from mistakes
- Why they are so powerful
- Where they are used in the real world
- The future potential of neural learning
By the end, you’ll understand neural networks in a way that’s both intuitive and accurate.
What Exactly Is a Neural Network?
Neural networks are the backbone of modern artificial intelligence. Although they are inspired by the structure and behavior of the human brain, they function through mathematical operations and layered processing. To understand how they learn, it’s important to first understand what they are made of and how they operate at a basic level.
Basic Definition
A neural network is a computational model designed to recognize patterns, make predictions, and improve continuously through experience. It consists of interconnected nodes—called neurons—that pass information to one another in a structured way.
In simple terms, a neural network is:
- A pattern-recognition system that learns from data
- A model that improves through repetition, adjusting itself each time
- The core engine of deep learning technologies
Neural networks don’t need explicit rules. Instead, they learn by observing examples and gradually figuring out relationships within the data—just like humans learn by seeing and practicing.
How Neural Networks Mimic the Brain
Although artificial neural networks are not biological, they borrow several essential principles from the human brain. The inspiration comes from how our neurons communicate, strengthen connections, and adapt through learning.
Key similarities with the brain:
- Neurons process signals and send them onward
- Connections strengthen or weaken based on experience
- Learning happens over repeated exposure to examples
Because of these similarities, neural networks can perform tasks that feel remarkably human.
This allows them to:
- Recognize objects in images
- Understand and generate language
- Predict future events, trends, or risks
- Identify patterns humans may miss due to complexity
In essence, they mimic the way humans analyze and understand the world—but at much larger scale and speed.
Components of a Neural Network
Every neural network—simple or advanced—is built from a few essential components. Each one plays a crucial role in how the network processes information.
1. Neurons
Neurons are the basic building blocks of a neural network.
Each neuron performs a small calculation.
A neuron typically:
- Receives inputs
- Applies a mathematical transformation
- Produces an output
When millions of neurons work together, they can understand extremely complex data.
2. Layers
Neurons are grouped into layers, and each layer performs a different part of the learning process.
A network usually includes:
- Input Layer
- Feeds raw data into the network
- Hidden Layers
- Extract features, find relationships, and transform data
- Output Layer
- Produces the final decision or prediction
The more hidden layers a network has, the “deeper” it becomes—hence the term deep learning.
3. Weights
Weights determine how important each input is.
They control how strongly one neuron influences another.
Why weights matter:
- High weight → input has strong influence
- Low weight → input has weak influence
- Zero weight → no influence
Learning in a neural network is largely about finding the right set of weight values.
4. Bias
Bias is an additional adjustable parameter that helps the neuron shift its output.
Bias helps by:
- Allowing flexibility
- Enabling the neuron to produce an output even when inputs are zero
- Improving the model’s ability to fit patterns
Bias works like the “fine-tuning knob” of prediction.
5. Activation Functions
Activation functions decide whether a neuron should “fire” or stay inactive. They give the network the ability to learn complex, nonlinear patterns.
Common activation functions include:
- ReLU (Rectified Linear Unit) – fast and effective, widely used
- Sigmoid – outputs probabilities in the range 0–1
- Tanh – similar to sigmoid but centered around zero
- Softmax – turns scores into a probability distribution
Without activation functions, neural networks would behave like simple linear calculators and fail to solve real-world problems.
How Neural Networks Learn: The Complete Process

Understanding how a neural network learns reveals the hidden “thinking” behind modern AI. The learning journey happens in a cycle of four major steps: forward propagation, loss calculation, backpropagation, and optimization. Each step plays a specific role in transforming raw data into accurate predictions.
Let’s break down each stage in a clear and intuitive way.
Step 1: Forward Propagation – Making a Prediction
Forward propagation is the very first stage of learning. It’s where the network takes in data, processes it layer by layer, and produces a prediction—similar to how your brain interprets what you see or hear.
How it works (in simple terms):
- Data enters the input layer, such as an image, sentence, or numerical value.
- It passes through multiple hidden layers, each transforming the information in its own way.
- The data is multiplied by weights, shifted by biases, and passed through activation functions that decide what signals move forward.
- Finally, the network produces an output, such as a class label, value, or probability.
Example:
- Input: Picture of a cat
- Output: “Cat (92% confidence)”
At this stage, the network simply guesses based on its current knowledge—even if it’s wrong. The real learning happens next.
Step 2: Loss Calculation – Measuring the Error
After making a prediction, the neural network must evaluate how close—or far—it was from the correct answer. This is where the loss function comes into play.
What the loss function measures:
- How wrong the prediction was
- How large the gap is between the network’s guess and the true label
- Where the model needs improvement
Why loss matters:
- High loss → The model is doing poorly and needs significant correction
- Low loss → The model is learning and getting closer to the right answer
Loss is like a teacher telling the network, “Here’s how much you messed up.”
The bigger the mistake, the bigger the correction required.
Step 3: Backpropagation – Learning From Mistakes
Backpropagation is the heart of neural learning.
It’s the process where the model learns from its errors and figures out exactly how to improve.
What happens during backpropagation:
- The error signal travels backward from the output layer toward the input layer.
- The network calculates gradients, which indicate how much each weight contributed to the error.
- It identifies which neurons and connections were beneficial—and which were harmful.
In simple, human-like terms:
Backpropagation tells the network:
- “Increase this weight—it helped.”
- “Decrease that weight—it caused a bigger mistake.”
- “This neuron made a good decision—strengthen it.”
- “This neuron didn’t contribute—reduce its influence.”
By distributing the blame correctly, the network learns what to adjust for the next attempt.
Step 4: Weight Optimization – Updating the Network
After the network identifies which parameters need to change, it performs optimization. This is where weight updates happen, gradually improving the model’s accuracy.
Most common optimizer:
- Gradient Descent — the core method used to adjust weights in the right direction and minimize loss.
Optimization updates:
- Weights — adjusting their strength
- Biases — shifting outputs for better alignment
- Network behavior overall — making the model more confident and accurate
Each update is small, but over thousands—or millions—of iterations, the network becomes highly reliable and intelligent.
Intuitive Analogy: How Neural Learning Mirrors Human Learning
One of the easiest ways to understand neural networks is to compare them to how children learn. Children don’t become experts overnight—they develop understanding slowly, through exposure, mistakes, and gentle correction. Neural networks follow this same natural learning pattern, making the analogy both intuitive and powerful.
Imagine Teaching a Child to Recognize an Apple
When a child encounters something new, they don’t instantly know what it is. Instead, they rely on observation, trial, and error.
Here’s how the process unfolds:
a. You show the child an apple for the first time, letting them take in its shape, color, and texture.
b. The child makes a guess based on what they already know: “Is that a tomato?”
c. You correct them by gently explaining, “No, this is an apple.”
d. The child adjusts their understanding—now associating the rounded shape, red color, and smooth skin with “apple.”
Each interaction helps the child refine their internal mental model. The next time they see a similar fruit, their guess becomes more accurate.
How a Child’s Learning Actually Works
Children get better not because they memorize a single example, but because they go through a repeated cycle of learning and correction.
a. They see multiple examples—big apples, small apples, green apples, red apples.
b. They make guesses based on similarities and differences.
c. They receive feedback from parents, teachers, or their environment.
d. They update their understanding by correcting earlier misunderstandings.
Through repetition, patterns become clearer, and recognition becomes automatic.
Neural Networks Learn Exactly the Same Way
Despite being mathematical systems, neural networks learn in a remarkably human-like manner. They don’t start with perfect knowledge—they start with guesses.
Here’s their learning cycle:
a. They receive data, such as an image, sentence, or sound.
b. They make a prediction based on their current understanding.
c. They compare the prediction with the actual correct answer.
d. They adjust their internal weights to reduce future mistakes.
This feedback-and-correction loop is repeated thousands—or even millions—of times during training.
Why This Human Analogy Matters
Just as a child becomes more confident and accurate with experience, a neural network improves as it processes more and more examples.
- More exposure leads to deeper understanding.
- More mistakes mean more opportunities for refinement.
- More correction results in better accuracy over time.
By the end of training, a neural network can recognize patterns with precision that often rivals or surpasses human ability.
Types of Neural Networks
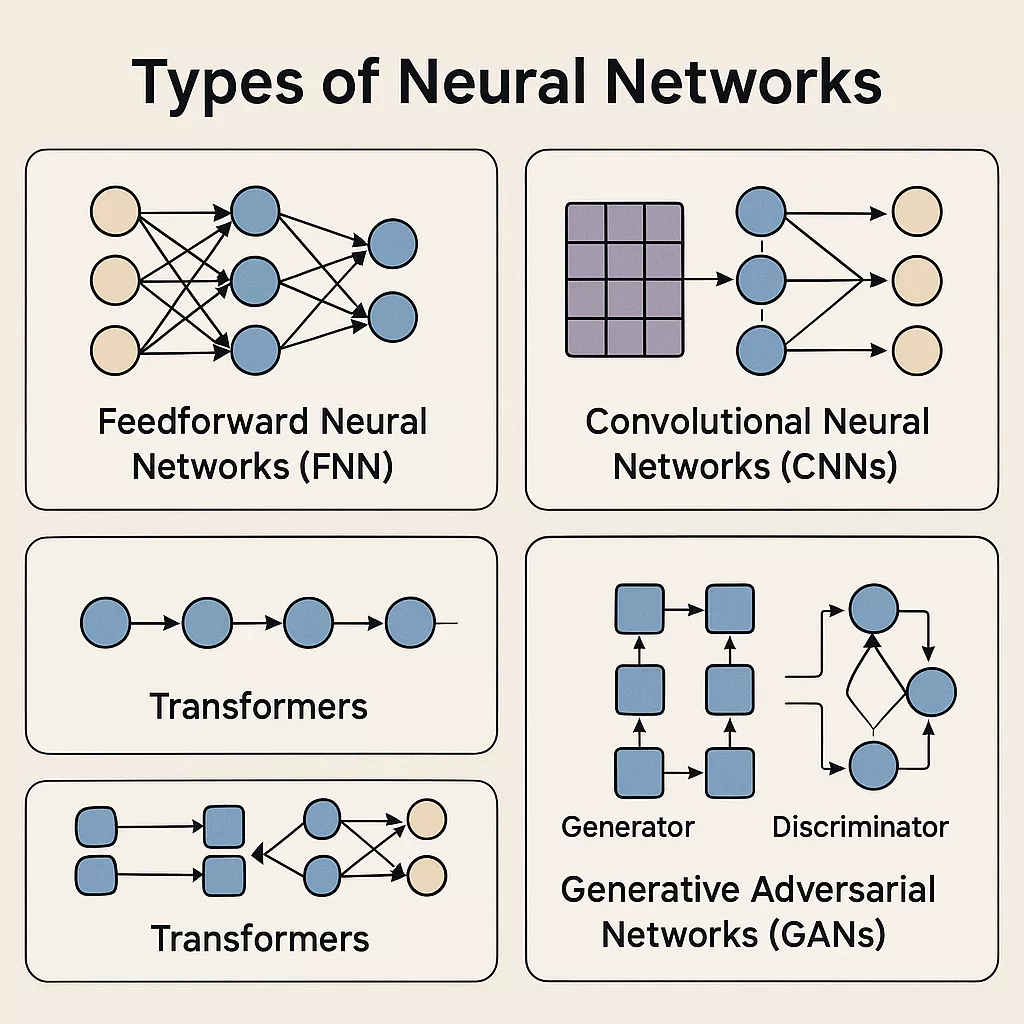
Neural networks come in many different forms, each designed for specific types of data, tasks, and real-world applications. While they all share the same basic principles—layers, neurons, weights—their structures and capabilities can vary dramatically. Below is a detailed, easy-to-understand breakdown of the most important types of neural networks used today.
1. Feedforward Neural Networks (FNN)
Feedforward Neural Networks are the simplest and most foundational type of neural network. Information flows in one direction—from input to output—without looping back. Because of their straightforward structure, they are often the starting point for understanding deep learning.
What makes FNNs important:
- They are easy to build and train.
- They work well for structured, non-sequential data.
- They form the basis for more advanced neural architectures.
Common uses include:
- Basic predictions such as demand forecasting or score estimation
- Fraud detection where patterns in transaction data must be identified
- Scoring systems like credit scoring or risk scoring
- Simple classification tasks such as spam vs. non-spam
FNNs may be simple, but they remain essential in many business and analytical applications.
2. Convolutional Neural Networks (CNNs)
Convolutional Neural Networks are specifically designed to analyze visual data. They use filters (convolutions) to scan images and detect patterns such as edges, textures, shapes, and objects.
Why CNNs are powerful:
- They automatically extract image features without manual labeling.
- They handle large, high-dimensional image data efficiently.
- They learn visual hierarchies—from simple edges to complex objects.
CNNs are widely used in:
- Facial recognition for unlocking phones or verifying identity
- Medical imaging, including X-rays, CT scans, and MRIs
- Self-driving cars to detect lanes, pedestrians, and road signs
- Object detection for security and surveillance
- Satellite image analysis for agriculture, climate, and disaster mapping
CNNs are the backbone of nearly all computer vision systems today.
3. Recurrent Neural Networks (RNNs)
Recurrent Neural Networks are built to handle sequential data, where order and context matter. Unlike FNNs, RNNs have looping connections that allow information to persist from one step to the next.
Why RNNs matter:
- They remember previous inputs through internal memory.
- They can handle text, audio, and time-based data naturally.
- They understand patterns that unfold over time.
Popular applications include:
- Speech recognition, such as converting audio to text
- Language modeling, predicting the next word in a sentence
- Time-series forecasting for stock prices, weather, or sensor data
- Music generation by learning rhythm and style patterns
Advanced RNN variants like LSTM (Long Short-Term Memory) and GRU (Gated Recurrent Unit) were developed to solve memory limitations, making them more capable of learning long-term sequences.
4. Transformers
Transformers are the most advanced and influential neural architecture in modern AI. They completely changed the field by enabling models to understand context, relationships, and meaning across long sequences—all without the limitations of RNNs.
What makes Transformers groundbreaking:
- They process entire sequences in parallel, making them extremely fast.
- They use self-attention mechanisms to focus on important parts of the data.
- They scale to massive models with billions of parameters.
Transformers power today’s most powerful AI systems:
- ChatGPT and advanced conversational models
- Google Gemini and multimodal AI tools
- Large language models (LLMs) across the industry
- Real-time translation systems like Google Translate
- Content generation, including text, code, and summaries
Transformers are the current state-of-the-art in natural language processing, reasoning, and multimodal AI.
5. Generative Adversarial Networks (GANs)
Generative Adversarial Networks are unique because they involve two neural networks competing with each other—one generating data and the other evaluating its authenticity.
How GANs work:
- Generator: Creates new content such as images or audio.
- Discriminator: Judges whether the content is real or AI-generated.
- Through competition, both networks improve dramatically.
GANs are used for:
- AI-generated art and creative visuals
- Deepfake creation, including realistic faces and voices
- Image repair, such as restoring old or damaged photos
- Style transfer, where one image adopts the style of another
GANs opened the door to a new era of AI creativity, enabling machines to generate content that looks and feels human-made.
Real-World Applications of Neural Networks
Neural networks have become the silent engine behind many technologies we use daily. Their ability to learn patterns, process huge volumes of data, and make accurate predictions has transformed industries across the world. Below are some of the most impactful real-world applications, explained in a clear and engaging way.
A. Healthcare
Neural networks are revolutionizing healthcare by improving diagnostic accuracy and enabling personalized treatment. These systems can analyze medical images far faster than humans and identify subtle abnormalities that might go unnoticed.
i. Early tumor detection through advanced imaging analysis
ii. Interpretation of X-rays, CT scans, and MRI results with higher precision
iii. Predicting patient risks for conditions like stroke, heart disease, or sepsis
iv. Creating personalized treatment plans based on patient history and medical data
By learning from millions of medical images, neural networks help doctors detect diseases earlier, improve patient outcomes, and reduce diagnostic errors. They serve as an intelligent assistant, complementing rather than replacing human expertise.
B. Transportation
The transportation industry heavily depends on neural networks to create safer, more efficient, and smarter mobility systems. From autonomous driving to traffic optimization, AI is reshaping how vehicles perceive and respond to their surroundings.
i. Understanding road environments for self-driving vehicles
ii. Predicting traffic flow to reduce congestion
iii. Optimizing routes for logistics and delivery companies
iv. Monitoring drivers to detect fatigue or unsafe behaviors
Neural networks process real-time data from cameras, sensors, and GPS systems, enabling transportation systems to become more reliable and responsive.
C. Finance
Financial institutions rely on neural networks to detect patterns that humans might miss. Their ability to process complex, high-volume data streams makes them ideal for tasks requiring precision and speed.
i. Spotting fraudulent transactions instantly
ii. Powering algorithmic trading systems that react to market changes
iii. Improving risk scoring models for loans and credit approvals
iv. Segmenting customers based on financial behavior
Neural networks identify anomalies and trends faster than human analysts, helping banks and financial companies make more informed decisions while reducing risk.
D. Retail & E-commerce
In the retail and e-commerce world, neural networks shape what customers see, buy, and experience. They analyze user behavior to personalize recommendations and optimize business operations.
i. Suggesting personalized products based on browsing and purchase history
ii. Adjusting prices in real time through dynamic pricing models
iii. Forecasting product demand with high accuracy
iv. Understanding customer behavior to improve user experience
Platforms like Amazon, Netflix, and YouTube rely heavily on neural learning to keep users engaged and satisfied.
E. Cybersecurity
Cybersecurity threats are growing in complexity, and neural networks offer a powerful defense by identifying unusual patterns that could indicate attacks. They work continuously, analyzing millions of data points every second.
i. Detecting intrusions before they cause damage
ii. Identifying malware based on behavior and signature patterns
iii. Flagging anomalies in network traffic
iv. Analyzing user behavior to prevent unauthorized access
Because neural networks learn from both past attacks and new trends, they can recognize malicious behavior in real time—far faster than traditional security systems.
F. Entertainment & Media
Neural networks are shaping the future of digital entertainment. They enhance creativity, improve content quality, and help platforms deliver more relevant experiences.
i. Recommending movies, videos, and music tailored to personal preferences
ii. Assisting in video editing, color correction, and image enhancement
iii. Powering AI-generated audio, artwork, and virtual characters
iv. Moderating social media content to filter harmful or inappropriate posts
From TikTok’s “For You” feed to Netflix’s recommendations, neural networks are central to how entertainment platforms keep users engaged.
Training Workflow (Step-by-Step)
Training a neural network is a structured and iterative process. It involves preparing data, choosing the right architecture, teaching the model through repeated cycles, and finally deploying it into real-world applications. Each stage plays a crucial role in ensuring the model performs accurately, efficiently, and responsibly. Below is a detailed breakdown of how a neural network is trained from start to finish.
1. Data Preparation
Before a neural network can learn anything, the data must be prepared properly. High-quality training data is the foundation of a strong model. This stage ensures that the network receives clean, consistent, and meaningful information.
- Data must first be cleaned, which involves removing duplicates, fixing errors, and handling missing values.
- It is then labeled, especially for supervised learning tasks where the model must learn from correct examples.
- Finally, the inputs are normalized, scaling them into consistent ranges so the network can process them efficiently without bias toward larger numerical values.
Proper data preparation dramatically improves training stability and accuracy.
2. Feature Extraction
Not all raw data is immediately useful. Feature extraction helps refine the input so the neural network can learn from the most important patterns without being distracted by irrelevant details.
- The process begins with identifying useful patterns in the data, such as edges in images or key phrases in text.
- Weak or irrelevant information is filtered out, reducing noise that might confuse the model.
- The remaining signals are enhanced, making patterns clearer and easier for the neural network to recognize.
This step increases learning efficiency and reduces the risk of the model being overwhelmed by unnecessary complexity.
3. Model Selection
Choosing the right model architecture is critical because different problems require different neural network structures. This stage shapes the model’s ability to learn and generalize.
- Developers must decide which architecture best suits the task—for example, CNNs for images or Transformers for language.
- They then choose the number of layers and how complex the model should be, balancing performance with computational cost.
- Finally, the activation functions are selected to determine how neurons behave and what kinds of patterns the model can learn.
Model selection sets the blueprint for how the network will interpret and learn from data.
4. Training Loop
The training loop is where the actual learning happens. This cycle runs repeatedly—sometimes millions of times—until the network becomes accurate.
- The forward pass processes inputs through the network and generates a prediction.
- The model then performs loss calculation, determining how far the prediction was from the correct answer.
- During backpropagation, the network identifies which weights contributed to the error and computes the necessary adjustments.
- Finally, weight updates are applied, improving the model’s performance for the next cycle.
This loop continues until the model reaches satisfactory accuracy, becoming more intelligent with every iteration.
5. Evaluation
Once training is complete, the model must be tested to ensure it performs well beyond the controlled training environment.
- The network’s accuracy is tested using data it has never seen before.
- It is checked for overfitting, which occurs when the model memorizes training data instead of learning general patterns.
- The model is then validated across multiple datasets to confirm that it behaves reliably in different scenarios.
Evaluation ensures the model is robust, fair, and ready for real-world use.
6. Deployment
After the model has proven its performance, it is ready to be integrated into real-world applications. Deployment marks the transition from testing to practical use.
- The model is embedded into apps, platforms, or devices, depending on the use case.
- It undergoes real-world testing to ensure it performs consistently under actual conditions.
- Continuous monitoring begins, allowing developers to track performance, identify issues, and update the model as needed.
Deployment is not the end—it’s the beginning of the model’s life in production, where it must evolve with new data and user needs.
Challenges in Neural Network Learning
Training neural networks is powerful, but not without difficulties. From data limitations to ethical concerns, several challenges can affect accuracy, fairness, and reliability. Below is a refined breakdown of these challenges along with their solutions.
A. Overfitting
- Description:
The model performs extremely well on the training data but fails to generalize to new, unseen data. It essentially “memorizes” instead of “learning patterns.” - Solutions:
- Regularization: Adds penalties to overly complex models.
- Dropout: Randomly deactivates neurons during training to prevent dependency on specific patterns.
- More diverse data: Expands training variety, helping the model generalize better.
B. Underfitting
- Description:
The model is too simple or underpowered to learn meaningful patterns, resulting in poor performance on both training and test data. - Fixes:
- Add more layers: Increases model depth for improved learning capacity.
- Increase complexity: Use more sophisticated architectures or parameters.
- Improve feature engineering: Provide richer, more relevant inputs.
C. Data Requirements
- Description:
Neural networks require large, high-quality datasets. Insufficient data can lead to weak learning or biased predictions. - Challenges include:
- Data collection: Gathering massive datasets takes time and resources.
- Annotation costs: Human labeling can be expensive and labor-intensive.
- Privacy concerns: Sensitive data (e.g., medical, financial) must be handled responsibly.
D. Compute Requirements
- Description:
Training modern deep learning models often demands powerful hardware—sometimes multiple GPUs or specialized TPUs. - Impact:
- Slower training if hardware is limited
- Higher operational costs
- Accessibility barriers for small teams or individuals
E. Bias & Fairness
- Description:
If training data contains biases, the model may unintentionally learn and amplify unfair patterns, leading to harmful or discriminatory outcomes. - Fixes:
- Diverse datasets: Ensure representation across groups.
- Bias detection tools: Identify and mitigate unfair patterns.
- Ethical oversight: Review models for transparency, fairness, and responsible use.
F. Interpretability
- Description:
- Many neural networks operate like “black boxes,” making it extremely challenging to understand how they reach their conclusions. This lack of transparency becomes especially problematic in high-stakes fields such as healthcare, finance, legal decisions, and security systems.
- Challenges:
- Difficult to explain decisions in complex models like deep neural networks
- Limited visibility into how features influence predictions
- Risk of hidden errors that remain undetected without clear reasoning
- Impact:
- Harder to debug errors because the decision pathway is unclear
- Reduced trust from users, auditors, and regulatory bodies
- Slower adoption in industries requiring transparency and accountability
The Future of Neural Networks
a. Efficiency Improvements
Neural networks are becoming far more efficient, enabling powerful AI models to run on smaller devices without heavy cloud dependence. Techniques like model compression, quantization, and edge AI allow high-level intelligence to operate on smartphones, wearables, and embedded systems. This shift makes AI faster, more accessible, and more energy-efficient.
b. Multimodal Intelligence
The next generation of neural networks will understand multiple types of data at once—including text, images, audio, video, and sensor input. By combining these modalities, AI systems will form a richer, more human-like understanding of the world. This capability unlocks advanced applications like real-time scene interpretation, interactive assistants, and unified AI systems that can reason across different information sources seamlessly.
c. Autonomous Learning Systems
Future neural networks will be able to learn continuously from real-world interactions rather than relying only on pre-collected datasets. These autonomous learning systems will refine themselves over time, adapting to user behavior, environmental changes, and new information. This continuous evolution will make AI more dynamic, personalized, and capable of long-term improvement.
d. AI Agents
AI agents represent a major leap forward—systems capable of acting independently, making decisions, solving problems, and carrying out tasks without constant human input. These agents will navigate digital environments, automate workflows, communicate with other systems, and assist humans across a range of industries. They mark the transition from passive AI tools to active AI collaborators.
e. Industry-Specific Architectures
As neural networks mature, more models will be purpose-built for specialized domains. Architecture designs will be tailored to the unique demands of industries such as medicine, law, engineering, and robotics. These industry-specific networks will offer higher accuracy, stronger compliance, better reliability, and faster performance by focusing on domain-specific patterns and requirements.
Summary: How Neural Networks Actually Learn
Neural networks learn by repeatedly adjusting their internal weights as they process data. Each learning cycle begins with a prediction, followed by a comparison between the guess and the correct answer. The difference – known as error – guides the network in updating its parameters so it performs better next time. Through thousands or even millions of these cycles, the model gradually transforms from taking rough guesses to making highly accurate, reliable predictions.
In essence, neural networks learn the same way humans do—through exposure, correction, and continuous improvement—ultimately becoming powerful tools capable of recognizing patterns, solving complex problems, and driving the future of intelligent systems.