
The AI Lifecycle is the iterative, end-to-end framework that guides an artificial intelligence project from its initial conception and problem definition through to data collection, model development, deployment, and ongoing monitoring. Unlike traditional software development, which is often linear, the AI lifecycle is cyclical; deployed models must be continuously monitored for performance degradation (drift) and retrained with new data to remain effective. This structured approach ensures that AI systems are not just experimental code, but scalable, reliable, and ethical business solutions that deliver tangible value.
Introduction: From “Cool Demo” to Production Reality
In the rush to adopt Artificial Intelligence, organizations often underestimate the complexity required to keep a model running effectively in the real world. A stark reality checks the enthusiasm: industry research indicates that over 80% of AI projects fail – nearly double the failure rate of traditional IT projects (Alberti et al., 2024). Furthermore, by the end of 2025, it is estimated that at least 30% of Generative AI (GenAI) projects will be abandoned after the Proof of Concept (POC) phase due to poor data quality or unclear business value (Alberti et al., 2024).
Understanding the AI lifecycle is the antidote to these failures. It transforms AI from a “black box” experiment into a manageable engineering discipline, often referred to as MLOps (Machine Learning Operations). This guide details every stage of the life cycle, supported by recent statistics and real-world examples, to help you navigate the path from idea to impact.
The 6 Critical Stages of the AI Lifecycle
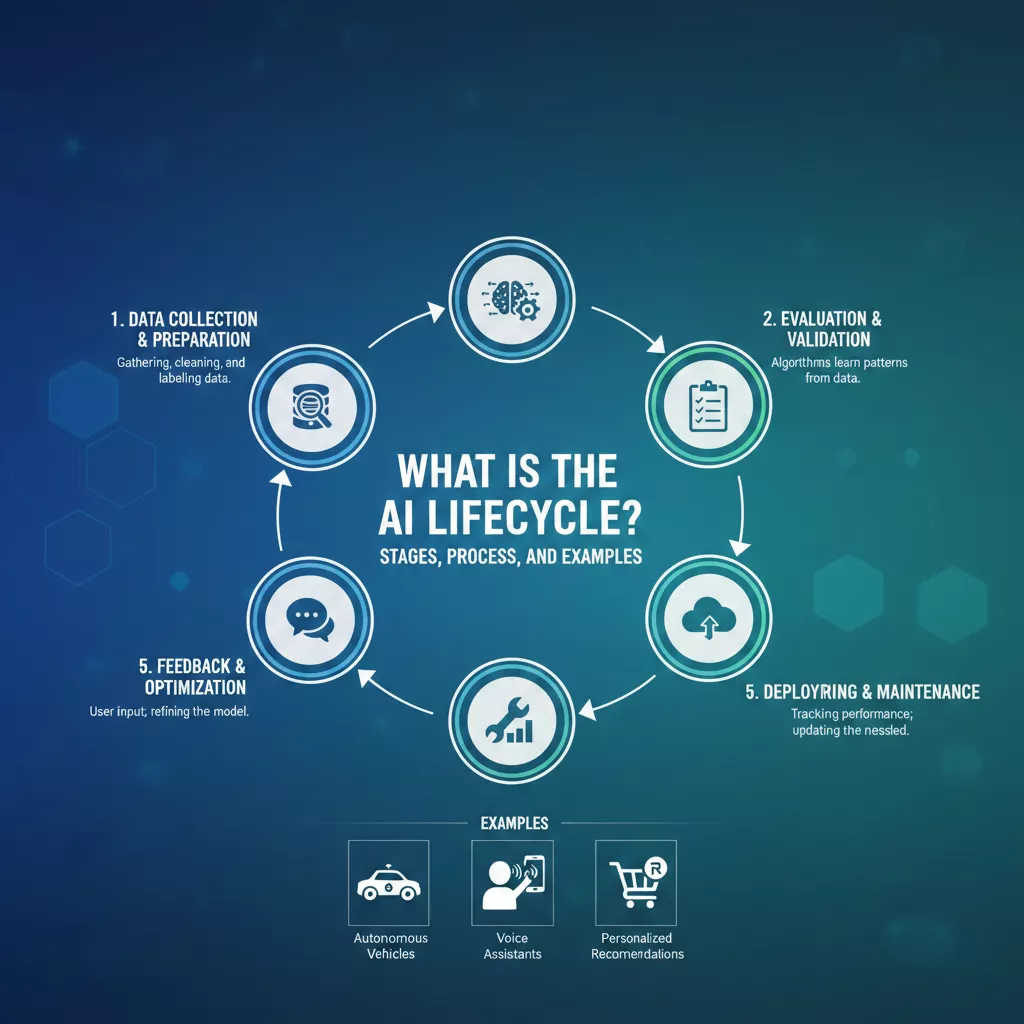
The AI lifecycle is generally divided into six distinct phases. While the terminology may vary slightly between organizations (e.g., IBM’s “AI Ladder” or Microsoft’s “Team Data Science Process”), the core progression remains consistent.
Stage 1: Business Scoping and Problem Definition
Before a single line of code is written, the team must define what they are solving and why. This is the “Scoping” phase. A common pitfall is starting with the technology (“Let’s use a Large Language Model”) rather than the problem (“Our customer service wait times are too high”).
- Key Activities:
- ROI Estimation: Calculating the cost of error. For example, in predictive maintenance, a missed failure (False Negative) can cost 50 times more than a false alarm (False Positive) (Abogunrin et al., 2025).
- Feasibility Analysis: Do we have the data? Is AI actually the right tool, or would a simple rule-based system suffice?
- Metric Definition: Choosing business metrics (e.g., “reduce churn by 5%”) and translating them into proxy technical metrics (e.g., “F1-score > 0.85”).
Stage 2: Data Acquisition and Preparation
This is widely cited as the most labor-intensive phase. Recent surveys identify insufficient data quality and readiness (43%) as the primary obstacle to AI success (Alberti et al., 2024).
- Data Sourcing: Collecting raw data from internal databases (SQL), APIs, or external vendors.
- Data Labeling: For supervised learning, humans must annotate data (e.g., doctors marking tumors on X-rays). This process is expensive and prone to bias.
- Preprocessing: Cleaning “dirty” data—handling missing values, normalizing scales, and removing outliers.
- Feature Engineering: Transforming raw data into inputs the model can understand (e.g., converting a timestamp into “Day of Week”).
Note on GenAI: In Generative AI projects, this stage involves “Data Curation” for RAG (Retrieval-Augmented Generation) systems, ensuring the documents fed into the model are accurate and up-to-date.
Stage 3: Model Development and Training
Once data is ready, the “science” begins. This stage involves selecting the right algorithms and training the model to recognize patterns.
- Model Selection: Choosing between architectures (e.g., Random Forest for tabular data, Convolutional Neural Networks for images, Transformers for text).
- Training: The model “learns” by processing the training data. This requires significant computational resources (GPUs/TPUs).
- Hyperparameter Tuning: Adjusting the “knobs” of the model (learning rate, batch size) to optimize performance.
Stage 4: Evaluation and Validation
A model that performs well in a lab often fails in the real world. Rigorous testing is mandatory before deployment.
- Technical Metrics: Assessing Accuracy, Precision, Recall, and AUC-ROC.
- Business Validation: Does the model actually save money or improve user experience?
- Bias and Fairness Testing: Checking if the model performs equally well across different demographics (e.g., gender, race, age).
- Stress Testing: How does the model handle unexpected or adversarial inputs?
Stage 5: Deployment (Operationalization)
Deployment is the process of integrating the model into a live production environment where it can make decisions for end-users.
- Serving Modes:
- Real-time API: The user clicks a button, and the model responds instantly (e.g., ChatGPT).
- Batch Processing: The model runs once a night on millions of records (e.g., generating daily stock recommendations).
- Edge Deployment: The model runs directly on a device (e.g., FaceID on an iPhone) without needing the cloud.
- A/B Testing: Rolling out the model to a small percentage of users first to compare it against the old system.
Stage 6: Monitoring and Maintenance
This is the “missing link” in many failed projects. AI models are not static assets; they decay.
- Drift Detection:
- Data Drift: The input data changes (e.g., user behavior changes after a pandemic).
- Concept Drift: The relationship between variables changes (e.g., “spam” emails look different today than they did 5 years ago).
- Retraining: When performance drops below a threshold, the model must be retrained on fresher data.
- Governance: continuous auditing to ensure the model remains compliant with regulations like the EU AI Act.
Comparative Table: Roles vs. Lifecycle Stages
Successful AI projects require a cross-functional team. The following table illustrates who is responsible for what.
| Lifecycle Stage | Primary Owner | Key Collaborators | Output |
| 1. Scoping | Product Manager | Data Scientist, Business Stakeholder | Problem Statement, ROI Analysis |
| 2. Data Prep | Data Engineer | Data Scientist, Domain Expert | Cleaned & Labeled Dataset |
| 3. Modeling | Data Scientist | ML Engineer | Trained Model Candidate |
| 4. Evaluation | Data Scientist | QA Engineer, Ethicist | Validation Report |
| 5. Deployment | ML Engineer | DevOps, Software Engineer | Live API / Microservice |
| 6. Monitoring | MLOps Engineer | Data Scientist, Business Analyst | Performance Dashboards, Alerts |
Deep Dive: The Economics of AI Maintenance
Many organizations budget for development but fail to budget for the lifecycle’s tail end: maintenance. The cost of neglecting this can be astronomical.
The Cost of False Positives vs. Negatives
In industrial contexts, the AI lifecycle must account for “asymmetric costs.” For example, in a CNC machine predictive maintenance model, a “False Negative” (failing to predict a breakdown) might cost $25,000 in emergency repairs and downtime. A “False Positive” (scheduling a maintenance check when none was needed) costs only $500 (Abogunrin et al., 2025).
A standard “high accuracy” model might miss that single expensive failure. A lifecycle-aware model is tuned specifically to minimize the financial impact, not just the statistical error.
Generative AI Costs
For healthcare systems deploying Large Language Models (LLMs) to summarize patient notes, costs can spiral if not managed. Running a GPT-4 class model on 2,200 notes daily can cost over $4 million annually. However, by optimizing the lifecycle—using smaller, specialized models for routine tasks—this cost can be driven down to roughly $100,000 (Abogunrin et al., 2025). This highlights why the “Evaluation” phase must include economic modeling, not just accuracy checks.
Real-World Examples of the AI Lifecycle
Example 1: Healthcare (Kaiser Permanente)
- Scoping: Doctors were burning out from spending 43% of their day on data entry. The goal was to reclaim clinical time.
- Data/Modeling: They utilized “Ambient LLMs”—systems that listen to the doctor-patient conversation and automatically generate clinical notes.
- Evaluation: The system was tested to ensure it didn’t “hallucinate” medical facts.
- Deployment: Rolled out to clinicians.
- Result: The system reclaimed 15,791 hours in a single year (roughly 1,794 clinician days), allowing doctors to focus on patients rather than screens (Bajwa et al., 2021).
Example 2: Manufacturing (Predictive Maintenance)
- Scoping: A factory wanted to reduce unplanned downtime for CNC machines.
- Data: Sensors collected temperature, vibration, and sound data.
- Modeling: Developed a “Causal AI” model that understood why a machine failed, rather than just correlating variables.
- Monitoring: The system continuously monitors 10,000 machines.
- Result: Achieved an annual cost saving of $1.16 million by reducing false alarms by 97% compared to traditional statistical methods (Abogunrin et al., 2025).
Example 3: Finance (Mastercard – Decision Intelligence)
- Scoping: The challenge wasn’t just stopping fraud, but stopping “false declines.” Old rule-based systems were rejecting legitimate cardholders, causing frustration and an estimated $118 billion in lost sales annually for retailers—actually costing more than fraud itself.
- Data/Modeling: Instead of simple rules (e.g., “deny if transaction > $500”), they implemented a sophisticated neural network. This model analyzes thousands of data points in real-time, including historical shopping behavior, location, merchant risk profiles, and even the speed of typing on a device.
- Deployment: The model operates in real-time (under 50 milliseconds) for billions of transactions globally.
- Monitoring: The system uses active feedback loops. If a customer calls to say “Hey, that was me!”, the model updates immediately to learn that specific behavior is safe.
- Result: By analyzing the context rather than just the rules, the system reduced false declines significantly, potentially recovering over 20% of lost revenue for merchants while maintaining high security.
Example 4: Retail & Food Service (Starbucks – “Deep Brew”)
- Scoping: Starbucks wanted to improve the drive-thru experience and increase the “average ticket size” (amount spent per order) without slowing down service.
- Data: They integrated disparate data silos: store inventory, local weather, time of day, and popular combinations.
- Modeling: A reinforcement learning model was built to generate dynamic recommendations.
- Deployment: The AI was deployed to digital menu boards. If it’s a cold rainy morning, the board promotes warm oatmeal and lattes. If it’s a hot afternoon, it shifts to Frappuccinos. Crucially, it only recommends items currently in stock at that specific location.
- Result: This hyper-personalization drove a tangible increase in spend-per-visit and improved inventory turnover efficiency, proving the value of integrating logistics data with marketing AI.
Example 5: Agriculture (John Deere – “See & Spray”)
- Scoping: Traditional farming involves spraying herbicides over an entire field to kill weeds, which is expensive, wasteful, and bad for the environment. The goal was to spray only the weeds.
- Data/Modeling: The team collected millions of images of crops (corn, cotton, soy) versus weeds. They trained a Convolutional Neural Network (CNN) to distinguish between a healthy plant and a weed in milliseconds.
- Deployment (Edge Computing): Unlike the previous examples, this couldn’t run in the cloud (farms have bad internet). The model was deployed onto robust hardware directly on the tractor’s boom arms (Edge AI).
- Result: The system reduced herbicide use by up to 77%, saving farmers massive input costs and significantly reducing chemical runoff into the soil.
Why Do AI Lifecycles Break?
If the lifecycle is so well-defined, why do 80% of projects fail?
- The “POC Trap”: Teams build a Proof of Concept in a sandbox with perfect data. When they try to move to Stage 5 (Deployment), they realize the real-world data is messy, or the infrastructure can’t handle the latency requirements.
- Siloed Teams: Data Scientists build a model and “throw it over the wall” to IT for deployment. IT doesn’t understand the model’s requirements, leading to performance issues.
- Ignoring Drift: A model is deployed and celebrated. Six months later, it starts making bad loan recommendations because the economy shifted. Without Stage 6 (Monitoring), the company loses money before they realize the model is broken.
Conclusion
The AI Lifecycle is not a checklist; it is a continuous loop of learning and adaptation. As AI capabilities expand into Generative AI and agentic workflows, the lifecycle becomes even more critical. The days of treating AI as a one-off science project are over. Today, successful AI implementation requires a rigorous adherence to these six stages, ensuring that systems are robust, cost-effective, and trustworthy.
By respecting the lifecycle, organizations can move from the 80% who fail to the 20% who genuinely transform their industries.
Frequently Asked Questions (FAQs)
1. How does the AI Lifecycle differ from the traditional Software Development Lifecycle (SDLC)?
The primary difference is uncertainty and circularity. In traditional SDLC (like building a mobile app), the logic is deterministic—you write code, and it performs exactly as written. In the AI Lifecycle, the system learns from data, meaning the outcome is probabilistic and not guaranteed. Additionally, while software can often be “finished,” an AI model is never truly done; it requires constant retraining (the feedback loop) to prevent performance degradation as real-world data evolves.
2. Which stage of the AI Lifecycle takes the most time?
Industry consensus and surveys consistently point to Stage 2: Data Acquisition and Preparation as the most time-consuming phase, often consuming 60-80% of a project’s timeline. Cleaning unstructured data, handling missing values, and ensuring accurate labeling are manual and tedious tasks. If this stage is rushed, the model will inevitably fail, regardless of how advanced the algorithm is (a phenomenon known as “Garbage In, Garbage Out”).
3. What is “Human-in-the-Loop” (HITL) and why is it important?
Human-in-the-Loop (HITL) is a mechanism where humans actively interact with the AI system during its training or operation. It is critical in two stages:
- Training: Humans label data to teach the model (e.g., identifying cancerous cells in images).
- Operation: For high-stakes decisions (like loan rejections or medical diagnoses), the AI provides a recommendation, but a human expert makes the final call. This ensures accountability and acts as a safety net against model errors.
4. How does the Generative AI (GenAI) lifecycle differ from standard predictive AI?
While the core stages are similar, the GenAI lifecycle places a much heavier emphasis on Prompt Engineering and Evaluation.
- Data: Instead of just training, you are often “grounding” a pre-trained model with your own documents (RAG).
- Evaluation: Validating GenAI is harder because the output is open-ended text or images. You cannot just measure “accuracy”; you must measure “hallucination rate,” “toxicity,” and “relevance,” often requiring expensive human review or specialized “LLM-as-a-judge” automated testing.
5. Why is Model Drift such a major risk in the AI Lifecycle?
Model Drift occurs when the environment in which the model operates changes, making the model’s training obsolete. For example, a fraud detection model trained on 2020 spending habits would fail in 2024 because consumer behavior and scammer tactics have changed. Without a robust Stage 6 (Monitoring) strategy to detect this drift and trigger retraining, a company could lose millions in undetected fraud or lost revenue before realizing the AI has stopped working correctly.